As I woke up this morning I got greeted by a WordPress-ping that somebody (Chris Hellmuth, from https://www.render-blog.com/) had cross-referenced an earlier blog post of mine, about the first few fun steps of wrangling the Moana Motunui Island Model (see original post here)…. back then still with Embree and OptiX.
Chris’ blog talks about the next step of that voyage: making Moana render well with a GPU (and in particular, OptiX) : for his full post, look here: https://www.render-blog.com/2020/10/03/gpu-motunui/. It’s an interesting read indeed.
Now looking at this post, I got reminded that I never wrote about my own experiences with this … because of course, the very first thing I did when switching to NVidia two years ago was to start writing a OptiX-based renderer for Moana – there isn’t anything like a challenging model to find weak spots and painpoints, so of course that’s the first thing I did. At the time, getting Moana to run on a GPU wasn’t actually all that easy: Turing had only just come out, OptiX 7 wasn’t even out, yet, and though the – back then just released – RTX 8000 cards did finally have some “real” GPU memory (48GB, to be exact), dealing with a model of that size and complexity still wasn’t exactly easy.
The whole journey is actually a story of many fits and start (and re-starts, and re-re-starts, ….) because this model is so challenging on so many fronts – but still, I did get this to render some two years ago … but never shared any results from that. Initially this was because early version contained a lot of work-arounds for limitations that have since gone away: For example, OptiX 7 is much more effective at rendering this model than OptiX 6 was; and even OptiX 7 initially had some restrictions that required workaround (eg, at most 16 million instances). For the latter problem at some point I actually wrote some really cool tools – and most of a never-published paper – about the best way of transforming a more-than-16-million single-level instance model into a multi-level instancing model…. which is an interesting problem indeed … but I digress.
Another issue I initially had to fight a lot with was memory consumption: For the first version I did indeed need two 8000s coupled with NVLink, at least when loading textures and/or tessellating curves – I could actually replicate the “high-frequency” data like acceleration structures, but vertex positions, shading normals, textures, etc, were shared over NVLink. The latest version can squeeze it all into less than 48GBs (at some point I squeezed it into a 24GB RTX 6000!), so if you have more than one card you can actually have them render in parallel …. but again, i digress.
Yet another issue I ended up spending a truly unholy amount of time and brain power on is textures: the original textures for Moana come in Disney’s Ptex format, for which I couldn’t find any CUDA sampling code …. and doing texturing on the host (which yes, one can do, through managed memory and some nasty multi-pass thingys… just saying) kind-of defeats the purpose. So, eventually I ended up writing some additional tools that would bake out the ptex’es into little 8×8 or 16×16 textures for each invidual pair of triangles in this model, to throw those into some larger texture atlas (because no, CUDA does not like a few million tiny textures ![]() ), and then doing some fancy texture coordinate mapping to make bilinear hardware texturing work with that. Thinking about it, that problem alone would be a fun blog post to write about….
), and then doing some fancy texture coordinate mapping to make bilinear hardware texturing work with that. Thinking about it, that problem alone would be a fun blog post to write about….
Anyway. I digress. Again.
Having read Chris’ blog I was reminded that I should probably dig out some of that code I wrote these two years back. A lot has changed since then – in particular, the OWL library (that I initially wrote for pretty much this project!) has become quite a bit more mature; and a lot of the early limitations have since been lifted in OptiX. Anyway, I did manage to at least make this code compile again, so here’s the very first picture of I got after the first 10 minutes of re-activating whatever code of that I could still find:
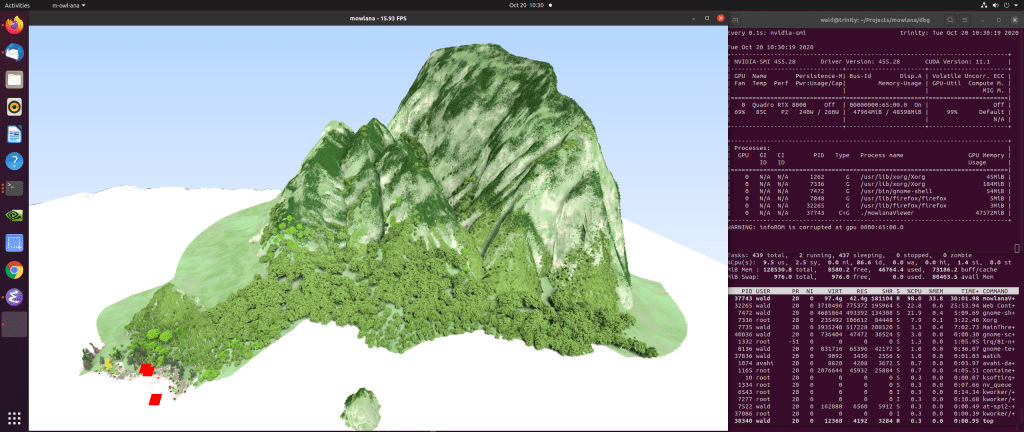
Quite obviously, this’ll need some more work to make it look pretty again: For some reason the water is now entirely white (it’s still a full path tracer, though, as you can see on the indirect illumination on the trees). Also, the environment map is missing in this pic, and the light sources are floating around as actual red square geometry pieces (on the beach, in the lower left). Also, memory usage is a bit higher than I remember (close on using the full 48GB, it should be less). Anyway – it still works. I’ll see if I can fix those missing pieces, and will post those, too, once done.
BTW: The entire project is – obviously – all written on top of OWL; in fact, it was one of the main drivers for this library, because it became pretty clear early on that if you want to focus your thoughts on what matters (like how to wrangle the content), then you really do want something that having something that takes the job of acceleration structure builds, Shader Binding Table construction, uploading of textures, buffers, etc, off your hand, and that you can reasonably rely on. Which, of course, reminds me of the fact that I still haven’t written about OWL. Which I should. And will. I promise.
With that: back to fixing that path tracer….
PS: In case anybody is wondering: roughly half of those 47GBs that it uses is textures ….
Update 1: Textures
Huh, as usual, it took a bit longer than expected, but here some first pic with real textures. The image above did contain some texels (quite a few, actually), but was actually buggy …. in my defense, I did say that dealing with this baking out is tricky. And it actually helps to realize that the pbrt file may actually contain the same logical texture in multiple different pbrt “ImageTexture” nodes. Here some first picture of one (!) of the corals. Gives you an idea of how massive this model really is: In the default picture, that entire shot will probably map to a single pixel (and is under the water).

Update 2: Envmap …
Turns out my github pbrtParser library I was using to load the model had somehow been broken over the course of the last few years, and didn’t actually “remember” any of the light sources again. Well, fixed that (which was a lot of work), after which making the environment map appear was as simple as using OWL’s recent support for 2D textures, and copying a few lines of code from Matt’s pbrt-v3 library (to match his fancy way of mapping from a ray direction to texture u/v coordinates).
And with that (four hours for the former, 15 minutes for the latter :-/) here we are once again with a proper environment map (and proper environment map lighting, of course):

(obviously that’s without the water and beach – still need to re-convert the full model after the parser fixes).
Also interesting how much of an impat the choice of lighting can have on the objects: here’s the same Coral as above, but now with the env-map lighting rather than a default “oversaturated white” that I used above: