
TL/DR: After having worked on this on and off for now roughly three years, our work on ray tracing really(!) large unstructured data on GPUs has finally been accepted at IEEE Vis; preprint here:

Short story long: This particular paper is part of a larger project that all started when NASA first released the Fun3D “Mars Lander Retropulsion Study” data at https://data.nas.nasa.gov/fun3d/ (with a HUGE “thank you” to Pat Moran for helping to get this data out into the community: Pat, we all owe you one!). This NASA project was about using supercomputing and numerical simulation (using NASA’s “Fun3D” solver) to simulate how a capsule entering Mars’ atmosphere could use “reverse” thrusters to slow down…. and generated a truly tremendous amount of data: The simulations were performed on three different model resolutions (each being a unstructured mesh with mostly tets, but also some wedges and hexes). The fun part: even the “smallest” version of that unstructured mesh was bigger than anything else I had been able to lay my hands on at the time, and the largest one having a solid 3 billion-ish unstructured elements (billion, not million)…. plus several different scalar fields, and many, many time steps.
Just downloading this data initially took me several weeks’ work, with initially a multitude of shell scripts to get all the files, check for broken data/interrupted connections, etcetc (that process has much improved since then…); and I also had to marshal quite some hardware for it, too: over the course of this project I not only got a whole stack of 48GB RTX8000 GPUs (from NVIDIA), I also bought – explicitly for this purpose – something on the order of about terabyte of RAM to upgrade two or three machines we used for data wrangling; and built two new RAID NASes (one 12TB, one 8TB) to deal with the resulting data.
On the software front, the effort to deal with this model was, if anything, worse: though we had plenty code to build on from some previous papers on tet-mesh point location and unstructured-mesh rendering, these codes initially were totally inadequate to deal with this scale of data – no matter how well a given piece of software works, once you throw something like two to three orders or magnitude larger data sizes at it you’ll find “where the timbers start to creak”. Well, that was the whole point of looking at this data, i guess…
Eventually, looking at this data quickly turned from “oh, a new data set to play with” to what turned into a major effort where pretty much each and every one of the tools we had been using before had to be completely rewritten to better handle data of that size; and where we ended up having to go into a whole lot of totally orthogonal directions that each had their own non-trivial challenges: building tools for even interfacing with unstructured meshes of that scale (our umesh library), different approaches to render it (with sampling vs tet/cell marching, different space skipping methods, different (adaptive) sampling methods, etcpp), with lots and lots of new helper tools for stitching, for computing mesh connectivity, iso-surfaces, shells, tetrahedralizations, partitionings, ghost-cells/regions, etcpp; a new framework for data-parallel rendering that can deal with this sort of data (where, for example, individual partitions aren’t convex), and so on, and so on, and so on….
What we realized at some point was that trying to write “one” paper about all of that simply wouldn’t work: there’s far too many individual pieces that one needs to understand for the others to make sense, and just not enough space in one paper to do that. So, to focus our first paper we decided to first describe and evaluate only exactly one particular angle of the whole project – namely, how far you could possibly “squeeze” the data required for a sample-based volume ray marcher operating on an unstructured mesh: given how expensive rendering this data is it was kind of obvious that we’d want to use GPUs for it – but for models of this size, the kind of algorithms and data structures we had used before were simply using (far) too much data. Consequently, one of the angles throughout this project was always to try and encode the same(!) data in a more efficient way, to try and fit ever larger parts of the data on a single GPU … until at some point we could fit all but the largest of the three versions of this data set (and even that largest one fits on two GPUs in a single workstation).
Unfortunately, even that single angle – how far you could possibly squeeze an instructured mesh and BVH to fit on a GPU (and how to best do that!) – turned into a non-trivial effort that in total we have now worked on (on and off) for over two years: part of that problem is the non-trivial amount of data wrangling, where even running one new variant of your encoding can take you another day to run through; but a totally unexpected one was just how much effort we had to put into evaluating/comparing that method. Reviewers (correctly so) asked questions like “how does that compare to tet marching” or “how does it compare to data parallel rendering” – and though these are absolutely interesting and valid questions, the problem for us was that there simply was nothing useful to compare against … so we eventually ended up having to solve all these totally orthogonal problems, too, just to be able to evaluate ours.
For example, just for something as simple as “comparing to tet-marching” you first need to have an implementation of tet-marching, so you need a tet marcher that can deal with this size of data … but before you can even start on writing the tet marcher you first need to have a tet-mesh neighborhood/connectivity information, and computing that for “several billion tets”-sized models (think hundreds of Gigabytes) isn’t exactly trivial, either …. and of course, you can’t even start computing the tet connectivity until you have a tet-only version of that model to start with, which in turn requires you to be able to robustly tetrahedralize a model with billions of mixed elements into another one with even more billions of tetrahedral elements, while properly handling bilinear quadrilateral faces etc while tetrahedralizing, etcpp … and if want to do your tet-marching in data-parallel (which you have to, because it’s too big for one GPU), then you also have to deal with partitioning, computing boundaries/”shells”, etcpp. If I include all this “extra” work required to make this paper, then there was probably far more effort required in doing this paper than in any other paper I’ve ever worked on… and with a healthy margin to spare.
Anyway; the first paper of this project is now finally “through” the reviewing pipeline, and has just been accepted at IEEE Vis 2021 (to later appear in TVCV). As said above this paper touches upon only one part of the whole project, and upon only one particular problem – one that’s an important ingredient to all the stuff around it, but nevertheless only part of the problem. A totally orthogonal aspect of that same “master project” has also just been accepted as a short paper at IEEE vis, but that’ll deserve its own blog post at some later time.
So for now: hope you’ll enjoy the above paper – it’s been a lot of work, but also a lot of fun. In case of any questions, feel free to drop me an email or leave a comment….. enjoy!
PS: Just a few of the images, to give you an idea of that data:
First, a volume rendering of the whole lander – note that there’s literally hundreds of millions of elements in that single view, and often dozens of tets per pixel (and not just in depth, but side by side!):
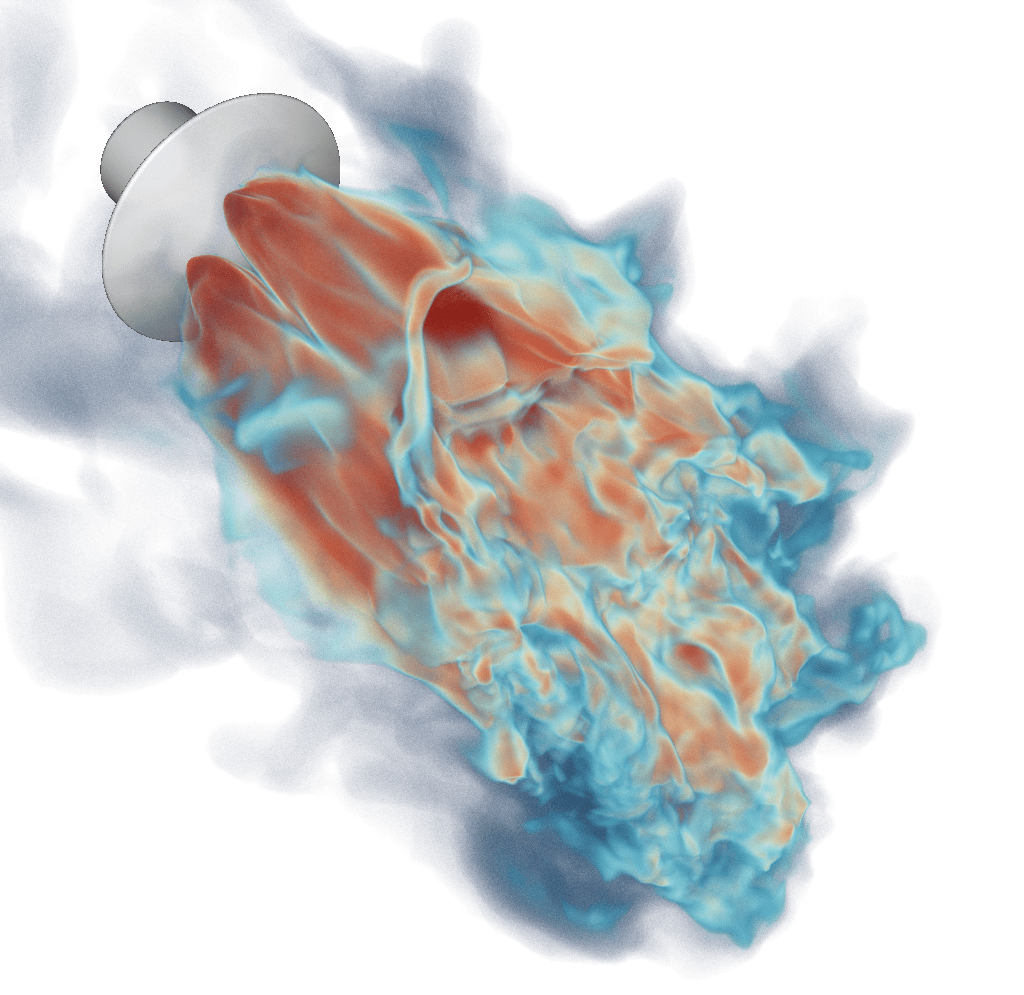
Now to give an idea of just how detailed the data behind this innocuous looking image is, here a is-surface that I extracted from that (yet another tool we had to write from scratch to deal with this size of data) :

Note this is for a different camera partition, but if you mirror it left-to-right you’ll probably see where they roughly match up. Doesn’t look too bad yet, because the tets (and thus, triangles) on the outside are much larger than those in the turbulent region, giving the totally wrong impression that the mesh wasn’t actually that fine: but this mesh alone is several hundred million triangles – and of course, is only a isosurface “cut” through the volumetric mesh.
Next let let’s use a color-coded version of this iso-surface, where different colors indicate some spatial pre-partitioning into blocks of already non-trivial models (remember, this is a isosurface from a volumetric mesh). As to how big each color-coded chunk is: I can’t say for sure (that image is over a year old), but I’m fairly certain those are the same as the “submeshes” we talk about in the paper, so roughly 64K vertices (maybe around 250K elements?) per chunk.

Now from that, let’s look at only the tiny region that is marked with a red square, and zoom in on that one, with the same “submesh ID” shader:
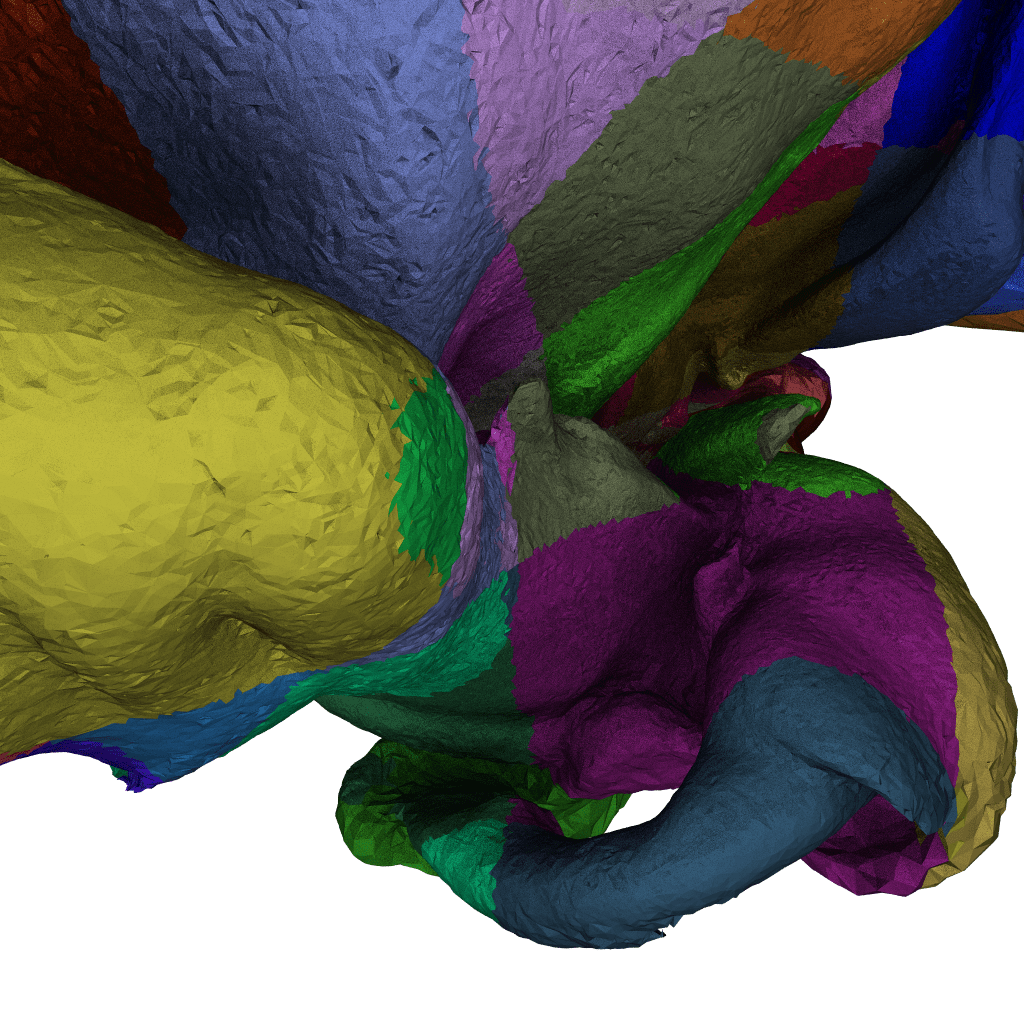
And finally, let’s take this same view, and render with a triangle ID shader to show individual triangles of this iso-surface:

Though hard to show in still images (it’s much more impressive if you can do that interactively 🙂 ), this hopefully helps in showing just how ridiculously finely tessellated this model is: each triangle you see in the iso-surface is roughly one tet in the volumetric model – except all the “whilespace” that the isosurface doesn’t show is full of tets (and other elements), too. And remember, that is only one tiny part of one plume of turbulence in the model, that in the beauty-shot above maps to just a handful of pixels… fun indeed 🙂

One thought on “New paper preprint: “A Memory Efficient Encoding for Ray Tracing Large Unstructured Data” (aka “the ‘bigmesh’ paper”), IEEE Vis 21”